Lessons From My First Product Launch
Today Chanel and I launched CloudVise, an AI advisor giving personalized advice across multiple topics. It was a long journey, starting all the way back in July.
Here are some lessons I learnt through the whole process.
Timeframes
I started work on the product right after I left my previous company, at the start of July.
The first 1-2 weeks were spent reading some nice fantasy books, relaxing, and brainstorming. Eventually I decided I would make a skeleton of an app first - something that could handle payments and logins, on a Python backend (FastAPI) and a NextJS frontend, hosted on AWS.
Initially I was very obsessed with Infrastructure-as-Code (IaC), since in my previous company, a lot of the deployment was manual. I started with a production-grade, scalable setup on AWS (with load balancers, containers via Elastic Container Service, and databases vs Relational Database Service).
After I set that up, I realized that it would cost me ~$50/month just for hosting a single product. So, I spent another week optimizing that setup (I managed to drop the monthly cost per product to $2.50 - you can read about that here).
I worked on the frontend in the last week prior to the product launch. Using AI tools was quite a big help here (I'm not very familiar with TailwindCSS).
Takeaways
Having a solid backend is important
Most people brush aside the backend as it is not something obvious to users, however from my past experience, a misfunctioning/unreliable backend can really turn users away. I was fortunate to have a codebase I had spent a lot of time refining over the previous months which I could adapt for this purpose.
A well designed backend should:
- be simple to understand (modular code)
- have functions which do only one thing
- not hardcode variables (so you can develop locally)
- have unit tests (ideally)
The usual principles of Clean Code apply.
Automated deployments speed up development time
I use Github Actions for CI/CD, using OpenTofu for deploying infrastructure. Once I make changes to the dev branch, merging them to prod triggers the pipeline and the production site is updated ~5 minutes later.
This is very helpful for testing production-only things like Stripe payments on the live account, or Google Analytics.
Nice frontend stuff
Tailwind CSS (for theming), Shadcn (for components) and Lucide Icons are a great combination. It's easy to swap themes via tweakcn, dark mode comes for free, and mainstream LLMs are very familiar with this stack.
Ads and Analytics
Google Ads and Google Analytics were very frustrating the first time I set it up. Some events were not being sent, I had no idea what a 'Google Tag' was, and so on. The Realtime Overview in Google Analytics even broke after I changed something. It was quite confusing and not clear where to see my accounts/properties/websites. After playing around for a while, I managed to get everything working.
Google Tag Manager (GTM)
This product allows you to embed various tracking tags into your website (e.g. for Google Analytics, Google Ads, Facebook etc) without having to update tracking code in your frontend each time. Instead, you can configure tags via the UI in Google Tag Manager.
An event in GTM refers to a unit of interaction you want to measure (e.g. button clicked, page scrolled, paged view, or custom Javascript fired an event).
Warning
GTM does not send events to tags automatically!
You need to setup Firing Triggers for a tag, which will send the event, and optionally any custom payload you configure to the tag's owner.
See the screenshot below for an example.
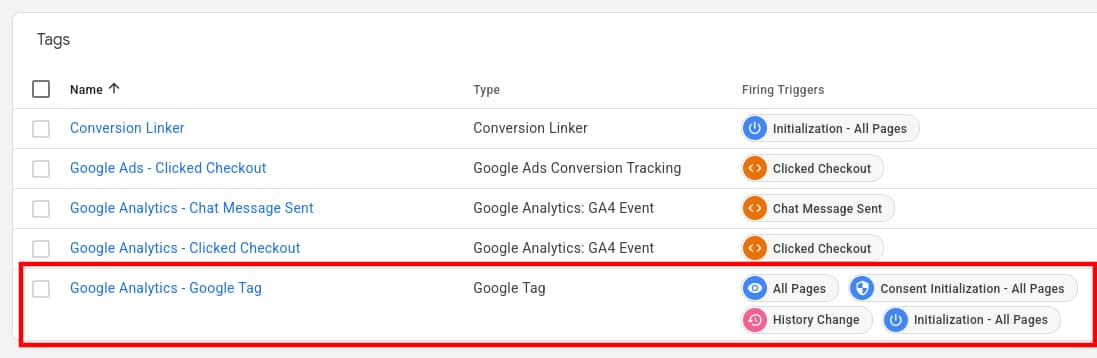
Of note, there is a new kind of tag available, (confusingly) called the Google Tag. This is a unified tag which:
- replaces multiple tags previously required for different Google products
- for Analytics, automatically sends interactions without further configuration
- for Ads, tracks conversions, including those via custom events
Google Analytics
I use Google Analytics to track engagement.
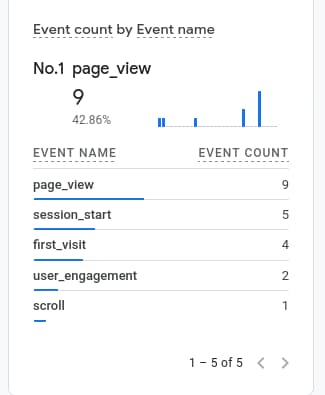
To send the new Enhanced Analytics events from Google Tag Manager (via the Google Tag), ensure that the Firing Triggers shown in the screenshot below are setup. These triggers are automatically converted in into meaningful events in Analytics, as shown below, without further configuration necessary ('All Pages' becomes page_view and so on).
You'll also notice that I have GA4 Event tags setup. These are for custom actions, such as when we push events to the Data Layer via Javascript (e.g. on checkout, or a chat message being sent). For example in NextJS, you can send a chat_submit event like this:
import { sendGTMEvent } from "@next/third-parties/google";
//...
const handleSubmit = useCallback(async (event: FormEvent<HTMLFormElement>) => {
event.preventDefault();
sendGTMEvent({ event: "chat_submit", topic: activeTopic?.title });
// ...
});
Custom events
Note that you cannot send custom events to the Google Tag directly in Tag Manager.
You need to create a new GA4 Event tag/Google Ads Conversion Tracking tag, which will (confusingly) use the Google Tag as its configuration.
Google Ads
In Google Ads, when you create a Campaign, you have 2 main ways of tracking conversions:
- Use Google Analytics' events (convenient)
- Send a custom event directly (via the Google Ads Conversion Tracking Tag)
Some sources on the internet say it is better to send a custom event directly, as that allows data to be sent to Google Ads faster for campaign optimization. I'm not fully sure about this yet (need to test).
Random thoughts about handling long-running jobs on the backend
I was randomly thinking about the best way to handle the scenario where the backend needs to make an API call to a vendor which might take a long time (e.g. video generation).
I initially thought we could just have the frontend wait for the backend to complete, but I realized this wasn't really feasible because long running HTTP connections can time-out on many layers (API Gateway has a 29s timeout, App Runner has a 120s hard timeout). What happens to the backend result if the connection is interrupted, but the vendor's request finishes?
There are 2 ways to solve the problem. Both involve asynchronous processing.
The first is to use a webhook from the vendor. This way, the vendor can notify the backend when the long-running job is complete, and the backend can then update the database accordingly. Meanwhile, the frontend continuously polls a backend endpoint to check the status of the job.
If the vendor does not have a webhook, then the second best option is to use a queue (e.g. Simple Queue Service). A queue offers features like message retention, dead letter queues to handle failures, and FIFO ordering.
In particular, an implementation of queue + function system (SQS + Lambda) for a low price could be:
Queue:
- message retention period 12 hours
- default visibility: 30s (how long we will wait for a worker to process, before making the message available to other workers again)
- maxReceives: 900 -> 1800s (30min) is max time we can wait for the vendor
- DLQ after that
A message comes in.
Worker (a Lambda function):
- first, check timestamp: if > 20min in queue, mark failed and send to DLQ
- check job status from the vendor:
- Success: get result, update DB, remove message.
- Pending: if this is the first run, block for 30s, then set the visibility timeout to something short like 5s. On each retry, check message age. If < 60s old → 2s visibility; if < 5m → 5–10s; if < 20m → 15–30s.
- Failed: send to DLQ, remove message.
DLQ handler:
- Update DB, remove message.
In the interest of saving money I checked the costs on GCP, which offers Cloud Run Worker Pools. The cost: 0.000011244 × 2,628,000 = 29.549232 (≈ $29.55). Minimum machine size: 1 vCPU, 512 MB RAM. This is still pretty expensive compared to using AWS Lambdas.