Music Management with Navidrome, DSub and Beets
Previously on Windows, I was using MediaMonkey to manage my music. It offered wireless syncing (over LAN) for the associated Android client, and worked well.
When I switched to Linux, I had to look for a replacement. I wanted a solution that was free and open-source, could be self-hosted on a server, and supported features such as bookmarks, playlists and transcoding (for clients not supporting certain formats).
After considering Airsonic, Funkwhale and Jellyfin, I settled upon Navidrome.
Navidrome
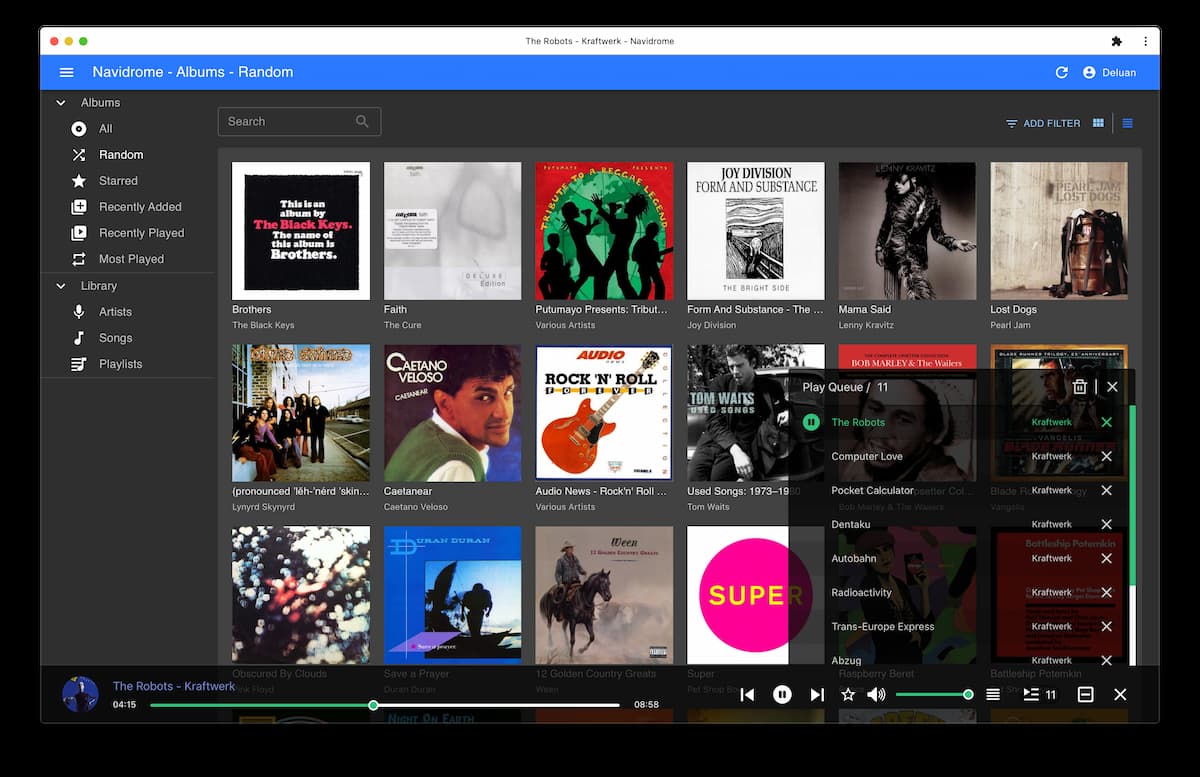
Navidrome is "an open source web-based music collection server and streamer", with support for on-the-fly transcoding1 for devices which cannot play certain formats (e.g. FLAC). It is accessible via the web. It also has Subsonic API support, which lets it work with the large variety of Subsonic clients available across platforms.
It also comes with a responsive, HTML5 web UI written as a progressive web app. Navidrome also keeps a record of play counts, recently played songs and also supports bookmarks, which is useful for audiobooks.
Additionally, multiple users can share a single server and maintain their own playlists.
DSub
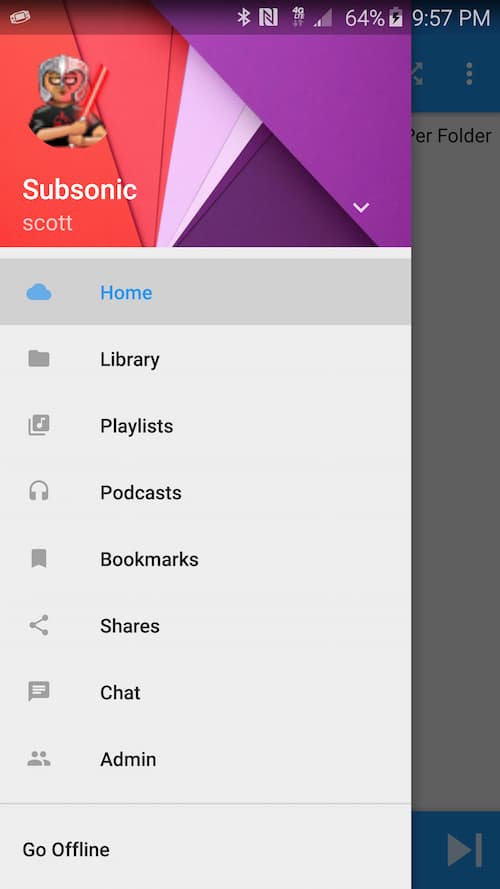
DSub (available on the F-Droid store) is the best Subsonic Android client in my opinion. It is the only client I have found which supports all of:
- Playlist managment
- Caching of audio files for offline playback
- Bookmarks
I cache songs in my playlists, which lets me listen to them when I don't have internet access.
Beets
I use the Beets CLI tool for tagging music and organizing. It supports fingerprinting audio files and looking up tag information from multiple sources.
I currently run Beets with several plugins in Docker.
Notes regarding playlist sync
At present, files which are renamed are removed from their playlists in Navidrome. This makes renaming/editing files with beets tricky, since there is nothing Navidrome can track to identify a file throughout renames/tag changes.
Initially I thought of using flexible attributes (non-standard tags), however they are not written into file metadata (they are only stored in beets' library), and are therefore not visible in Navidrome.
After exploring various options, here is a comparison between using different sources of truth for playlists:
| Task | Navidrome | .m3u playlist files | Tags + Smart Playlists (either Navidrome or in beets) |
|---|---|---|---|
| File rename/metadata change | Need to re-add those files to Navidrome's playlists if they were in any | Navidrome should automatically sync updates to playlist files | Navidrome updates automatically |
| Adding/removing playlist items | Can be done in Navidrome/clients | Manually edit playlist file, cannot be done from Navidrome/clients | Tags must be manually updated (via beets) |
| Advantages | Can use ffmpeg -i <filename> hash - to hash audio data (excluding metadata) |
beets can automatically update playlist files on library changeCan be version controlled |
Simple |
I rejected the first option (using Navidrome as the source of truth) as identifying which of the modified files are in Navidrome's playlists is a time-consuming task.
The decision between the second option (using playlist files) and the third option (using tags in files) came down to which method I preferred using to update playlist items: editing the playlist file, or editing file tags.
I decided on the third option, using tags in files with Navidrome Smart Playlists for the following reasons:
- Smart Playlists in Navidrome are read-only, so there is no danger of accidentally editing the playlist in Navidrome, versus importing a playlist file
- Editing tags is more convenient, and allows querying all playlists a song is in/vice versa, versus maintaining a playlist file
I use beets2 to modify the ID3 field comments3 to store the names of playlists the file is in: e.g.:
Subsequently in Navidrome, I have a smart playlist for each playlist, e.g. for Top Rated.nsp:
The playlists are then visible in Navidrome and automatically updated as new files are added.
-
Navidrome does not yet support per-format transcoding options (i.e. if you turn on transcoding for a client, Navidrome will transcode all files, irregardless of format, to the specified format. See this issue. ↩
-
You can use
beet info <query>to output metadata which is stored in the file (as opposed to flexible attributes, which are stored inbeets' database and not visible to Navidrome). ↩ -
Strangely,
beetsuses the field namecommentsto refer to the actualcommentfield (which is a canonical fieldname and which Navidrome uses). I haven't yet figured out the reason why. ↩